7 best LLM tracing tools for multi-agent AI systems (2026)
TL;DR: Quick comparison of the best LLM tracing tools:
- Best overall (multi-step workflow tracing, token-level tracing, step-level tracing): Braintrust
- Best open source LLM tracing: Langfuse
- Best for LangChain: LangSmith
- Best for ML + LLM: Fiddler
Great AI products are not built in a day. They are refined over thousands of iterations. The teams that win are the ones that can close the loop between a production failure and a fix the fastest.
LLM tracing is the infrastructure that makes this speed possible. Logs show you the final output. Traces reveal the execution path, the tool calls, the retrieval context, and reasoning steps that produced it.
This visibility transforms debugging from a guessing game into a systematic process. Instead of staring at a wrong answer, you see the exact chain of thought that led to it. High-performing teams use this granular data to improve their AI products with data rather than vibes.
What is LLM tracing?
LLM tracing captures structured logs of operations in your AI pipeline. When a request flows through your system, tracing records each LLM call, tool invocation, retrieval operation, and reasoning step as a span. These spans connect in a tree structure that shows the complete execution path.
Basic logging stores inputs and outputs. Tracing shows what happened in between. Token-level tracing captures prompt tokens, cached tokens, completion tokens, and reasoning tokens for every model call. Step-level tracing maps out multi-step workflows with parent-child relationships. The timeline replay shows the execution sequence and the timing for each span.
The difference shows up when things break. Logs tell you that an error occurred. Traces indicate the error happened on step 7 because the retrieval operation returned wrong documents, which caused the prompt template to inject bad context, which made the model hallucinate. One is a symptom. The other is a diagnosis.
7 best LLM tracing tools in 2026
1. Braintrust
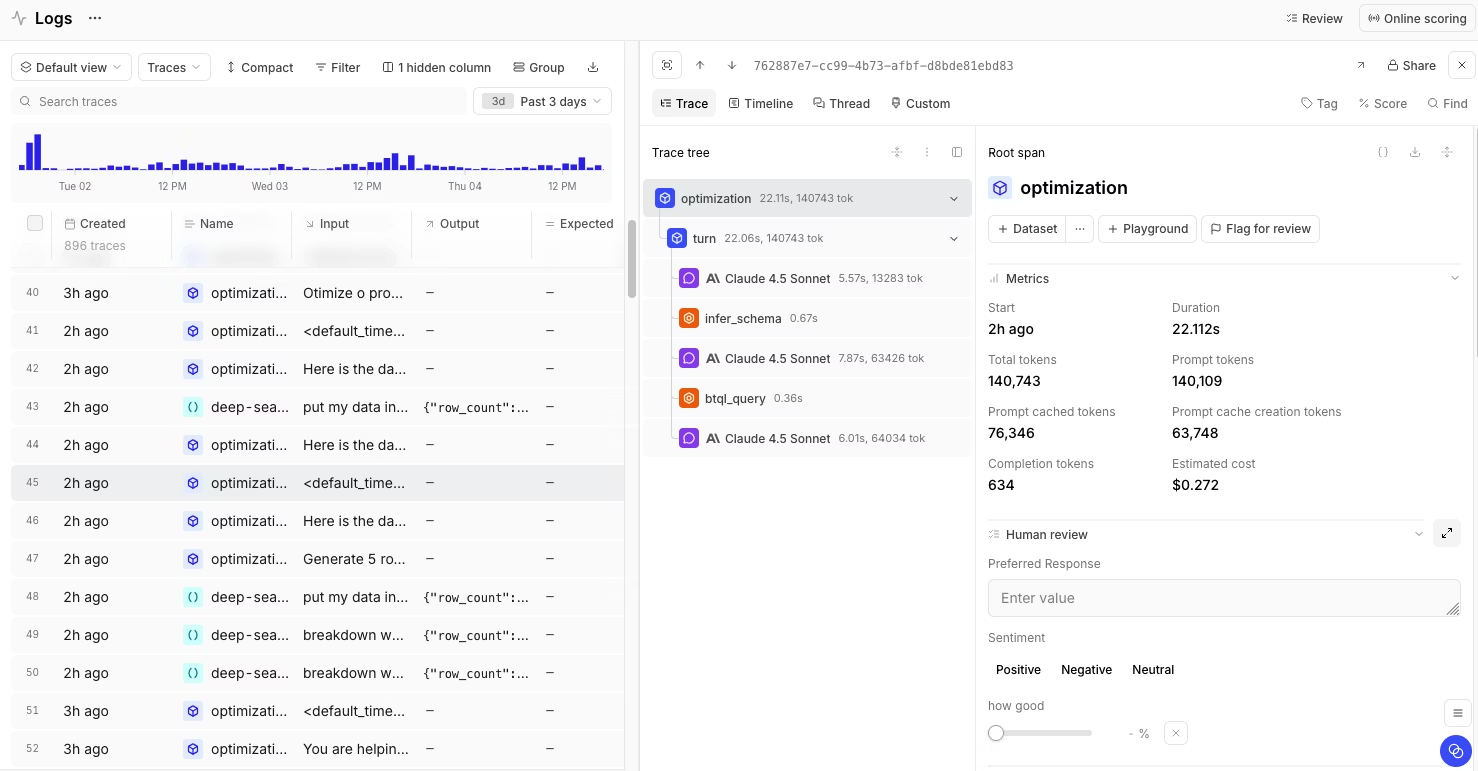
Braintrust captures exhaustive traces automatically and connects them directly to evaluation. Every LLM call, tool invocation, and retrieval step gets logged with full context. The platform is built for teams who need to move fast without breaking things.
The tracing interface shows complete execution paths for multi-step workflows. Each span displays token-level metrics, timing data, inputs, and outputs. When debugging complex agent runs, the timeline replay view makes it easy to spot where latency spikes occur or which tool call introduced bad data.
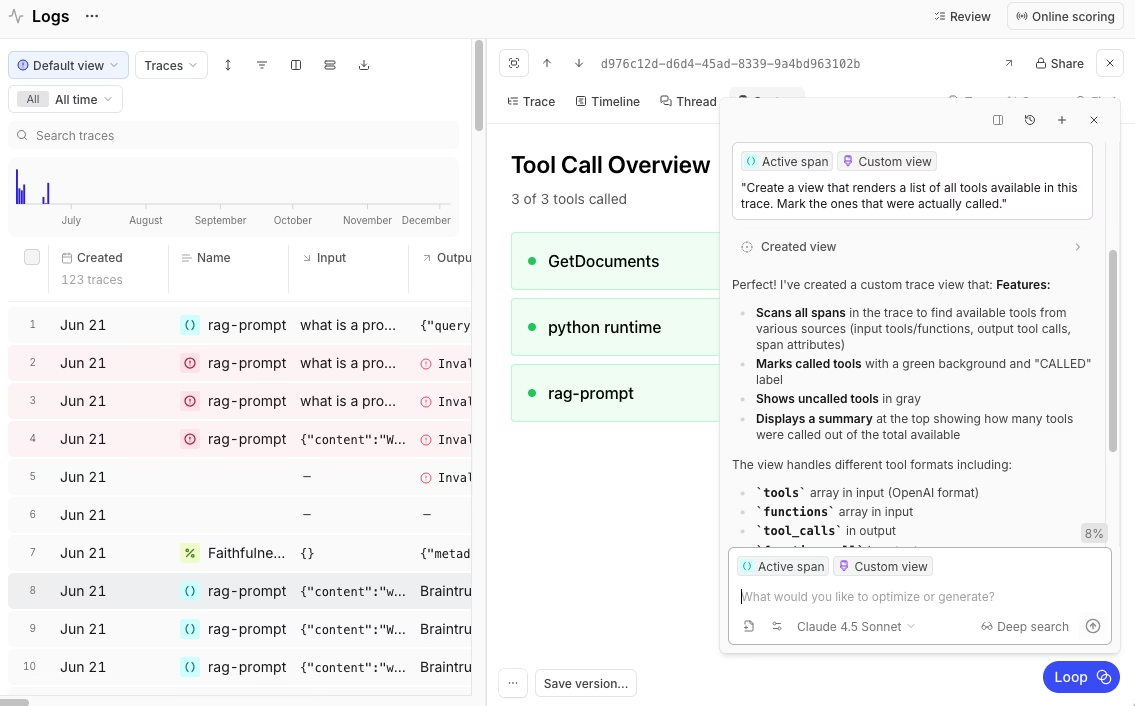
Error tracing connects failures directly to their root causes. When an agent workflow breaks, the trace view highlights the failed span and shows exactly what went wrong. You can see the prompt that was sent, the response that came back, and any errors that occurred. This prompt-to-error tracing eliminates hours of manual log parsing.
Braintrust's tracing infrastructure handles the scale of production AI data. LLM traces are significantly larger than traditional application traces, often tens of kilobytes per span. The platform's query engine keeps searches responsive even across millions of traces.
Best for: Teams building production AI systems who need comprehensive token-level tracing, step-level visibility, timeline replay, and seamless integration between tracing and evaluation.
Pros:
- Automatic trace capture with exhaustive metrics: Every trace logs LLM duration, time to first token, prompt tokens, cached tokens, completion tokens, reasoning tokens, estimated cost, tool calls, and errors. Token-level tracing works out of the box with no configuration. This automatic instrumentation captures detailed logs that make prompt-to-error tracing straightforward.
- Timeline replay for debugging workflows: Visual timeline replay shows when each operation started, how long it ran, and what it returned. For multi-step agent runs with 10+ tool calls, this view makes replaying agent workflows immediate. You can see latency tracking at each step and identify bottlenecks visually.
- Step-level workflow visibility: Nested spans show parent-child relationships in multi-step agent execution. Expand any span to see inputs, outputs, metadata, and timing. The tree structure makes workflow tracing through complex scenarios clear. Chain-of-thought visualization for reasoning models shows intermediate thinking steps.
- Error tracing to prompts: When failures occur, the trace shows which step broke and why. Error tracing separates LLM errors, tool errors, and timeout errors. You can trace errors back to prompts and see the exact template and variables that caused the problem. This prompt-to-error tracing eliminates guesswork in debugging.
- Fast queries at production scale: Filter and search thousands of traces in seconds. The platform runs on Brainstore, optimized for AI workloads. Query by error type, latency threshold, prompt template, model version, or user ID. Response times stay consistent even with millions of traces.
- OpenTelemetry integration: Accepts OpenTelemetry traces via OTLP with automatic span conversion. No manual configuration needed. Intelligent attribute mapping extracts LLM-specific information from standard OTLP traces. Works alongside existing OpenTelemetry infrastructure.
- Traces become eval cases instantly: Convert any production trace to a test case with one click. Failed traces become permanent regression tests. The native GitHub Action posts eval results directly to pull requests. This tight loop between tracing and evaluation accelerates iteration.
- Multiple trace views: Timeline view for replaying agent workflows, thread view for conversation-style interactions, and custom views you can create with natural language. For example, "show me all tool calls that took longer than 2 seconds" or "create a table of all retrieval operations."
- Cost tracking across providers: Automatic cost estimation per trace based on token usage and model pricing. See cost breakdowns by model, by operation type, and over time. Token-level logs show exactly where money gets spent.
- AI proxy with automatic tracing: Single OpenAI-compatible API for models from multiple providers. Every call through the proxy gets traced and cached automatically. Switch between OpenAI, Anthropic, and Google without changing code.
- Free tier that scales: 1M trace spans, 10k scores, unlimited users. Most teams stay on the free tier for months while building.
Cons:
- Self-hosting requires an enterprise plan
- Pro tier at $249/month may be expensive for solo developers
Pricing: Free (1M spans, 10k scores, 14-day retention), Pro $249/month (unlimited spans, 5GB data, 1-month retention), Custom Enterprise plans. See pricing details
2. Arize Phoenix
Arize Phoenix is an open source observability platform for LLM applications with OpenTelemetry-based tracing. The platform uses the OpenInference standard built on OTLP for capturing LLM-specific events.
Best for: Teams who want LLM tracing open source with OpenTelemetry compatibility.
Pros:
- OpenInference standard built on OpenTelemetry makes traces portable
- Sessions group traces by user for multi-turn conversation tracking
- Cost tracking with trace-level and span-level breakdowns
- Pre-configured metrics dashboards for latency, cost, and token usage
- Integrations for OpenAI, Anthropic, LangChain, AutoGen, CrewAI
Cons:
- Requires infrastructure knowledge for production deployments
- No built-in timeline replay feature
- Limited step-level tracing UI compared to dedicated platforms
Pricing: Free for open-source self-hosting. Managed cloud starting at $50/month. Custom enterprise pricing.
Read our guide on Arize Phoenix vs. Braintrust.
3. Langfuse
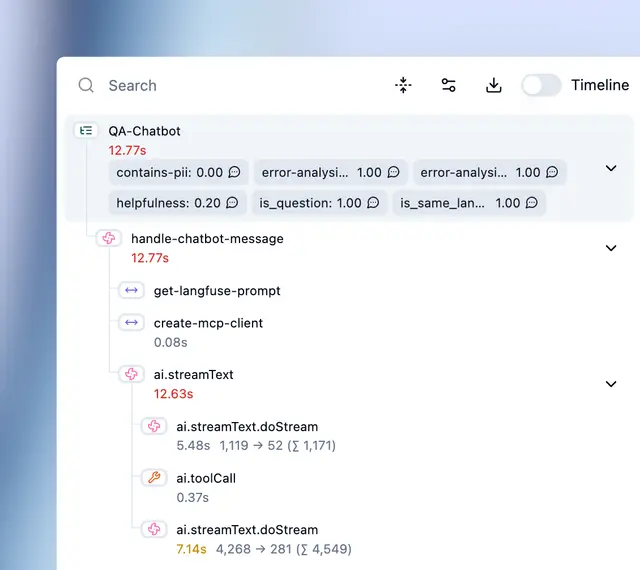
Langfuse is an MIT-licensed open-source platform for LLM tracing, prompt management, and evaluation. Self-host without restrictions or use their cloud. The platform focuses on giving teams complete control over their data.
Best for: Teams who want open-source LLM tracing with self-hosting flexibility and no vendor lock-in.
Pros:
- MIT license with unrestricted self-hosting
- OpenTelemetry integration pipes traces to the existing infrastructure
- Multi-turn conversation support tracks sessions across interactions
- Trace tree visualization shows parent-child span relationships
- Automatic token counting with cost calculation per trace
Cons:
- UI is functional but less polished than commercial platforms
- No built-in timeline replay or chain-of-thought visualization features
- CI/CD integration requires custom implementation
- Self-hosting production instances needs DevOps expertise
- Limited step-level tracing UI compared to dedicated platforms
Pricing: Free self-hosted and basic cloud tier. Paid plans start at $29/month.
Read our guide on Langfuse vs. Braintrust.
4. LangSmith
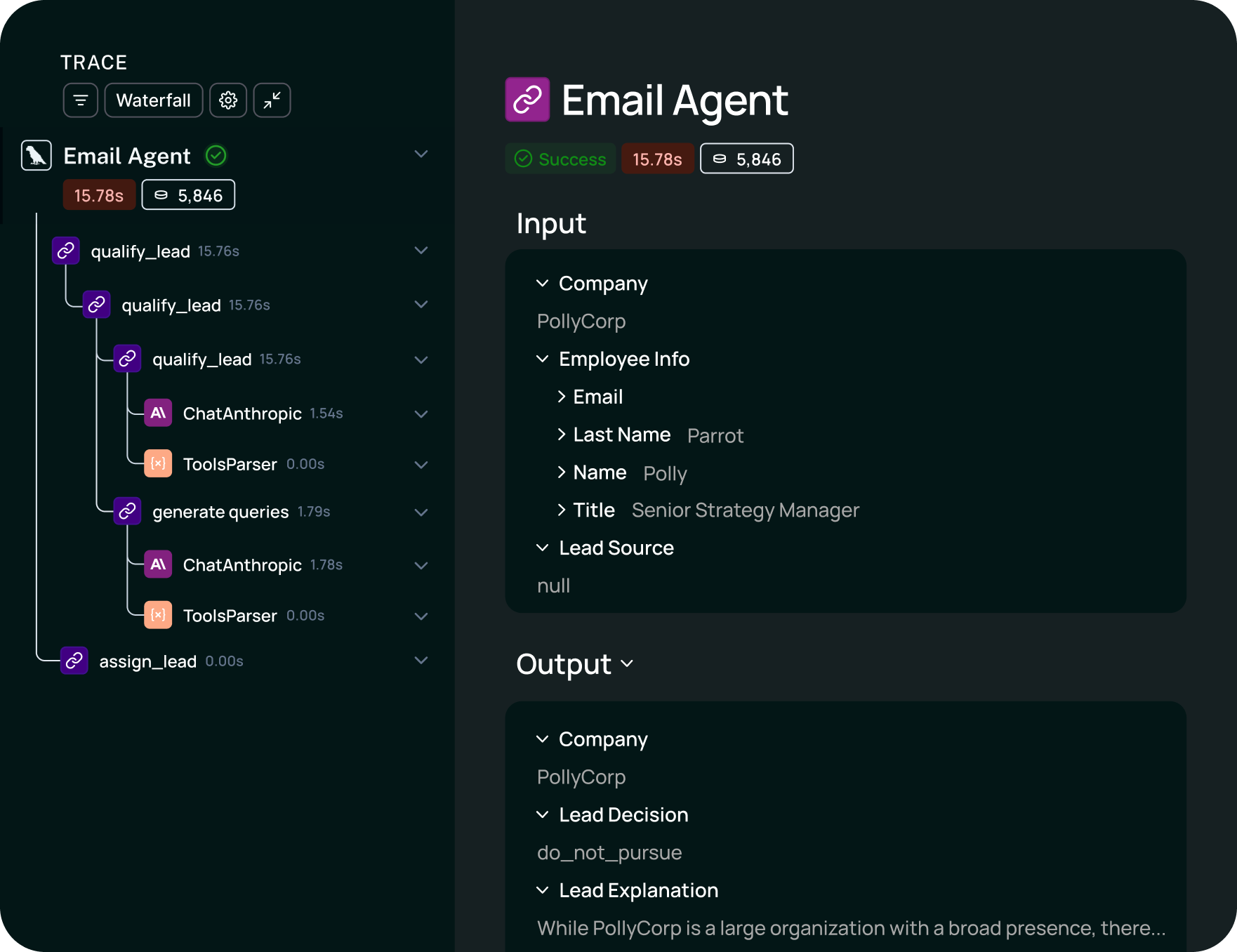
LangSmith is built by the LangChain team specifically for LangChain and LangGraph applications. If your stack is LangChain-based, setup takes one environment variable. The platform understands LangChain primitives and displays them natively.
Best for: Teams all-in on LangChain or LangGraph who want native workflow tracing with minimal setup.
Pros:
- Zero-config setup with one environment variable for LangChain apps
- LangChain-native UI understands chains, agents, and tools
- Timeline view shows execution sequence with timing per operation
- Built-in evaluation tools with LLM-as-judge support
- Live monitoring dashboards with configurable alerts
Cons:
- Best experience locked to the LangChain ecosystem. Other frameworks get basic support but miss native features
- Per-seat pricing becomes expensive as teams grow
- Self-hosting is only available on the enterprise tier
- Limited token-level tracing compared to platforms built specifically for that
- Free tier caps at 5k traces per month (compared to Braintrust's 1M trace spans), which even small teams hit quickly
Pricing: Developer free (5k traces/month), Plus $39/user/month (10k traces/month), Enterprise custom.
5. Maxim AI
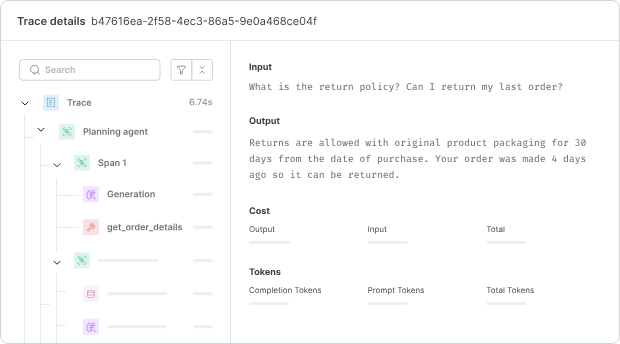
Maxim combines tracing, evaluation, and simulation into a single platform. It lets you test agent behavior across thousands of scenarios before shipping.
Best for: Teams building multi-agent systems who need visual tracing and pre-production testing.
Pros:
- Visual trace view shows agent interactions step-by-step
- Agent simulation engine tests across thousands of scenarios
- Pre-built evaluator library includes hallucination tracing
- SOC 2 Type 2 compliant with in-VPC deployment options
Cons:
- Newer platform with a smaller community means fewer resources and examples
- Some features, like the no-code agent IDE, are still in alpha
- Limited OpenTelemetry integration compared to platforms built on that standard
- Timeline replay and chain-of-thought visualization are less mature than dedicated platforms like Braintrust
Pricing: Free tier available, paid plan starts at $29/seat/month.
6. Fiddler AI
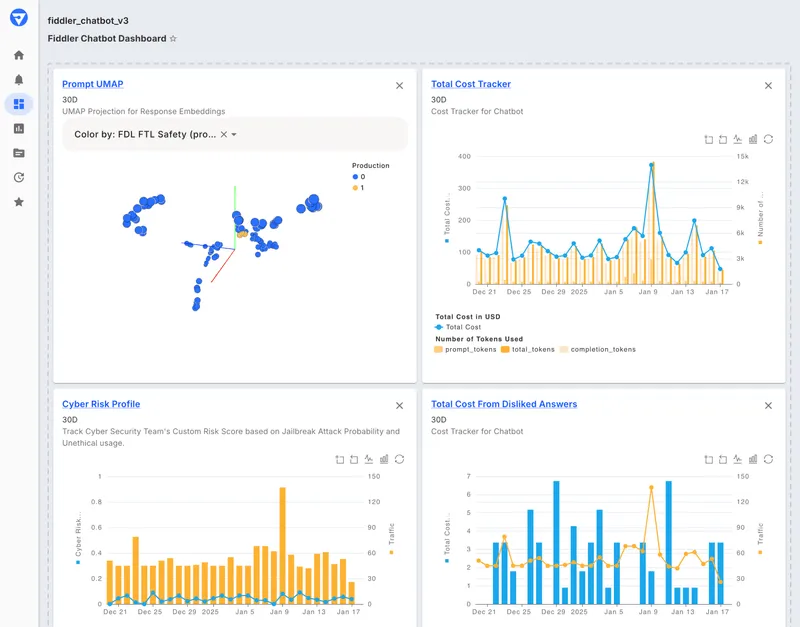
Fiddler monitors traditional machine learning models and LLM applications in one platform. The focus is on enterprise use cases requiring explainability, drift detection, and regulatory compliance.
Best for: Enterprises running ML and LLM workloads who need unified monitoring with compliance features.
Pros:
- Single dashboard for traditional ML models and LLM applications
- Explainability features include Shapley values and feature importance
- Drift detection tracks data quality and distribution shifts
- Segment analysis shows performance across user groups
- VPC deployment with SOC 2 compliance for regulated industries
Cons:
- Enterprise-only pricing requires sales conversation
- Steeper learning curve due to the breadth of ML and LLM features
- Better suited for organizations with dedicated ML platform teams
- Limited token-level tracing and workflow tracing compared to LLM-focused platforms
- No timeline replay or replaying agent workflows features
Pricing: Contact sales for enterprise pricing.
7. Helicone
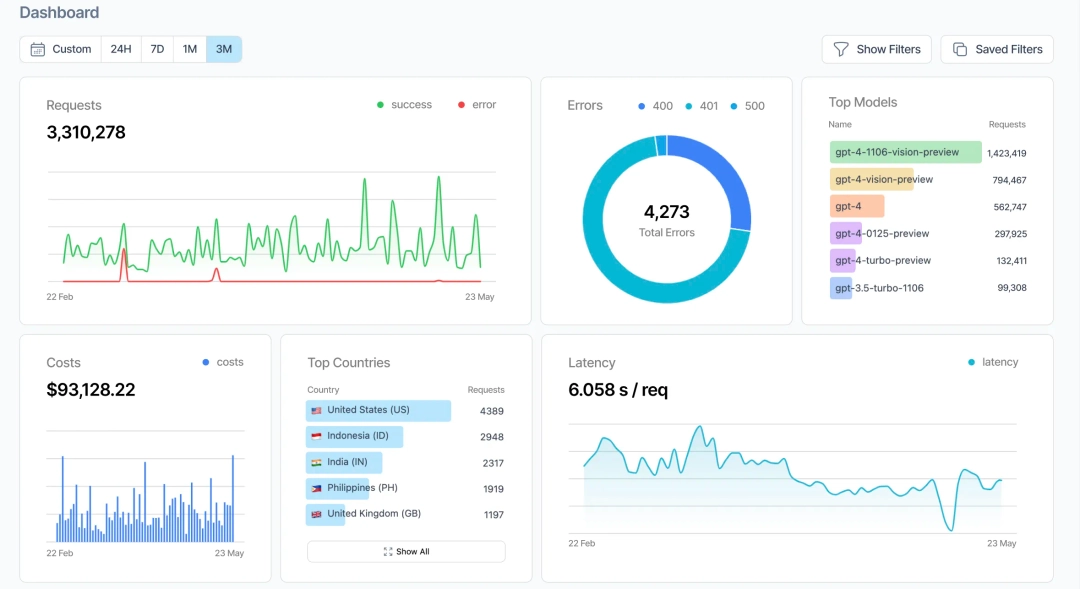
Helicone is an AI gateway with caching, routing, and basic tracing across 100+ models. The platform focuses on operational features like reducing costs through caching and providing failover between providers.
Best for: Teams who want gateway capabilities with basic LLM tracing.
Pros:
- Built-in caching reduces costs for duplicate requests
- Routes to 100+ models with automatic failovers
- One-line integration by changing the API base URL
- Session tracking for multi-step workflows
- Automatic token-level cost calculation
Cons:
- Basic tracing compared to dedicated platforms. Focuses on gateway features, not deep observability.
- No timeline replay, chain-of-thought visualization, or step-level tracing
- Limited error tracing capabilities compared to platforms built for debugging
- Less useful for teams that need comprehensive workflow tracing and replaying agent workflows
Pricing: Free tier (10,000 requests/month). Paid plan at $79/month.
Read our guide on Helicone vs. Braintrust.
Comparison: best LLM tracing tools (2026)
| Platform | Starting Price | Best For | Standout Features |
|---|---|---|---|
| Braintrust | Free (1M spans) | Production AI with token-level and step-level tracing | Timeline replay, prompt-to-error tracing, chain-of-thought visualization, instant eval integration |
| Arize Phoenix | Free (Self-hosting) / Free SaaS (25k spans) | Enterprise ML + LLM, open source | OpenInference standard, cost tracking, sessions, OpenTelemetry native |
| Langfuse | Free (Self-hosting) / Free SaaS (50k spans) | LLM tracing open source, data control | MIT license, OpenTelemetry support, self-hosting |
| LangSmith | Free (5k traces) | LangChain/LangGraph workflow tracing | Native LangChain integration, timeline view, zero-config setup |
| Maxim AI | Free (10k traces) | Multi-agent debugging, testing | Visual trace view, 1MB trace support, simulation engine |
| Fiddler AI | Contact sales | Enterprise ML + LLM compliance | Explainability, drift detection, unified monitoring |
| Helicone | Free (10k requests) | Gateway with basic tracing | Caching, 100+ model routing, simple integration |
Ship reliable AI agents faster. Start tracing for free with Braintrust
Why Braintrust is the best choice for LLM tracing
Most LLM tracing tools stop at showing you what happened. Braintrust closes the loop from observation to fix.
When you hit a production failure, other platforms make you export the trace, manually recreate the scenario, and wire up separate evaluations. With Braintrust, you click the failed trace and convert it to a test case that runs in CI on your next pull request. The loop from production failure to permanent regression test takes minutes, not days.
The platform handles production scale without tradeoffs. Token-level tracing captures prompt tokens, cached tokens, completion tokens, and reasoning tokens automatically. Step-level tracing maps multi-step workflows with parent-child relationships. Latency tracking breaks down timing per operation. The query engine keeps this fast across millions of traces. Filter by error type, latency threshold, or prompt template - results come back in seconds.
When an agent fails on step 8 of 19, timeline replay shows the exact sequence. Chain-of-thought visualization shows model reasoning at each decision point. Prompt-to-error tracing connects failures to specific template variables. You see the problem and fix it in the same interface.
The Playground lets you test prompt changes against real production traces immediately. See how your fix performs before shipping. Loop, Braintrust's AI assistant, helps you write scorers, generate eval datasets from traces, and identify failure patterns automatically.
Engineers and PMs work together without handoffs. A PM marks a bad response. The engineer sees the full trace with context. Custom views let non-engineers format traces without code. This shared workflow eliminates communication overhead.
The AI proxy makes tracing work across providers. One API routes to OpenAI, Anthropic, Google, and others. Every call gets traced and cached automatically. Switch models to compare performance using the same trace structure.
Other platforms give you tracing or evaluation. Braintrust gives you both in one system with the fastest path from production failure to permanent fix. That's why teams shipping AI products choose Braintrust for LLM tracing.
Ready to trace your LLM workflows end-to-end? Start free with Braintrust
When Braintrust might not be the right fit
Braintrust focuses on production LLM tracing with evaluation integration. Some scenarios where alternatives may be more appropriate:
- Open-source requirement: Braintrust is not open-source. For organizations with strict open-source requirements, Langfuse provides MIT-licensed LLM tracing with self-hosting.
- LangChain-exclusive stack: Braintrust supports LangChain, but LangSmith works with LangChain for framework-specific debugging.
- Gateway-only needs: Braintrust has an AI proxy for multi-provider routing. For teams focused purely on gateway functionality, OpenRouter is a great gateway for LLM calls.
- Combined ML and LLM monitoring: Braintrust specializes in LLM tracing and evaluation. Organizations monitoring both predictive models and generative AI may want to consider tools that focus on ML monitoring.
FAQs: top LLM tracing tools
What is LLM tracing?
LLM tracing captures the execution path of requests through AI systems. It records LLM calls, tool invocations, retrieval steps, and reasoning chains as structured spans that connect in a tree showing how requests flowed through your system. Good LLM tracing provides token-level metrics, step-level visibility, latency tracking, and error tracing.
Can you break down how token-level tracing actually works in modern LLM eval tools?
Token-level tracing captures prompt tokens, cached tokens, completion tokens, and reasoning tokens for each LLM call. Systems calculate cost based on actual consumption and model pricing. You see token usage at each span in the trace tree, showing which operations are expensive and where cached tokens save money.
Which is the best LLM eval platform for tracking traces?
Braintrust connects tracing to evaluation seamlessly. Production traces become eval cases with one click. The platform captures token-level tracing, step-level paths, timeline replay, and prompt-to-error tracing automatically. Eval results post to pull requests via GitHub Actions without exporting data.
What's the simplest QA stack for tracing agent workflows across multiple LLM calls?
Braintrust provides the simplest path. Install the SDK, wrap your LLM client, and automatic trace capture starts. Every agent run appears with timeline replay, step-level tracing, latency tracking, and error tracing. No manual instrumentation needed.
What tech stack helps PMs trace LLM errors to prompts?
Braintrust gives PMs and engineers a shared interface. The trace view shows which step broke, the exact prompt template, the variables, and the model response. Prompt-to-error tracing enables collaborative debugging without engineering bottlenecks.
How do I choose the right LLM tracing tool?
Evaluate on token-level and step-level detail, workflow tracing for multi-step agents, timeline replay for debugging, error tracing capabilities, and OpenTelemetry compatibility. Braintrust, if you need comprehensive tracing with evaluation. LangSmith, if you're all-in on LangChain. Langfuse, if you need open source.